the watchers, pt. 2: the correspondence
0x00 - prologue
part 1 dropped on february 16th. 53 megabytes of source code from a government endpoint. 269 verification checks. biometric face databases. SAR filings to FinCEN. the full codebase of the platform that verifies your ChatGPT account.
what happened next was… definitely not what i expected.
and then at 4:10 AM pacific on february 17th, less than 24 hours after publication, persona’s CEO emailed me directly. not outside counsel. not a legal threat. not a DMCA takedown. just… a person, asking to talk.
EFF published a piece. PC Gamer, Kotaku, The Rage ran coverage. Malwarebytes picked it up. Slashdot. HN frontpage. DL News, IBTimes, Wikipedia. discord ended their persona verification experiment. the thing moved faster than i could track it.
we exchanged 10 emails over 4 days. february 17-20. rick song responded to someone publishing his company’s source code by being a person about it. rare enough to be worth documenting.
so, as promised, this is our full correspondence.
emails are pasted here word for word, unedited. commentary goes between them, clearly separated. things i can verify independently (CT logs, DNS, public docs) are noted. things that are rick’s word only are noted as persona’s position. nothing inside the emails has been touched.
0x01 - the opening
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 17, 2026, 4:10 AM PST
subject: Open to talking re: Persona?Hi Celeste,
I’m Rick, one of the co-founders and CEO of Persona.
I came across your recent blog post (https://vmfunc.re/blog/persona) and wanted to reach out directly:
1/ Thank you for the callout re: shipping the source maps — we are looking into fixing this now!
withpersona-gov.comis currently under development and is not actively used right now. For context, we’re currently working through the FedRAMP process since there has been interest from a couple of agencies to provide identity proofing services for remote federal employees. We do not want our technology to be used by ICE or the government for any surveillance purposes.Unfortunately, providing the sourcemaps was an oversight by the team working on this, and we haven’t started an in-depth security review / pen test on the project yet given it’s still in early development.
2/ I’m happy to answer any/all of the 14 questions on your post about Persona and the way we operate to the best of my knowledge. For example, the Onyx name has no association with ICE (we weren’t even aware until your blog post!) — it’s actually named after a coworkers’ favorite Pokemon. We do not work with any federal agency today, and this is an unfortunate name…
Happy to answer over a call live on whatever platform works best for you (Zoom, Meets, Signal, or even Discord lol). In a past life, I was an engineer and I still make mediocre contributions to our codebase semi-frequently, so I can speak at a high-level regarding our technical architecture too.
I have some time tonight if that happens to work for you? Would love to provide clarifications to some of your points sooner if possible! I’ve also reached out over Twitter to @vmfunc in case DMs are more convenient.
Best,
—
Rick Song CEO | Persona https://withpersona.com
4:10 AM on a monday. less than 24 hours after the post hit.
he addresses source maps (fair, fixed fast, credit where due) and onyx (pokemon). doesn’t mention openai-watchlistdb. doesn’t mention the 27 months of CT logs. doesn’t mention the 18 questions in 0x14.
according to persona, the “onyx” naming is a reference to pokemon.
offers a call. zoom, meets, signal, discord. four platforms, all private, all ephemeral. understandable - it’s how people prefer to talk. but when your platform holds biometric data for millions of people, “we talked about it on a call” isn’t transparency.
“the 14 questions.” there were 18.
0x02 - the response
from: celeste <celeste@router.sex>
to: rick song <rick@withpersona.com>
date: february 17, 2026, 11:27 AM PST
subject: Re: Open to talking re: Persona?hiya rick, i appreciate you reaching out
thanks for not leading with lawyers. that already puts you ahead of most companies who find their entire codebase on the front page of hacker news, so genuinely, thank you
sending the CEO instead of outside counsel says something, and i want to acknowledge that
let me go through your points.
re: the source maps. glad you’re fixing it, but i need to be clear about what we’re actually talking about. this wasn’t a misconfigured S3 bucket on some forgotten staging box. this was unminified typescript served from /vite-dev/ on a FedRAMP-authorized government endpoint, that path is vite’s development server prefix. someone deployed a dev build to production on infrastructure that already went through federal security assessment. 2,456 source files. the full dashboard codebase of a platform that processes biometric data and files reports with FinCEN. that’s kind of really bad to be honest
respect for fixing it that fast btw, 2-3 hours is a pretty good response time
“we haven’t started an in-depth security review yet” is a sentence that should concern your compliance team more than my blog post does
FedRAMP authorization implies a baseline of security controls that should catch exactly this. the fix isn’t pulling the source maps, you should fix this by explaining how this passed assessment in the first place
re: onyx and the pokemon. i hear you, and i genuinely hope that’s the real story. unfortunately there is no way i can fully trust you here and you know this, but i’m trying to act in good faith. the blog post explicitly states we found zero references to fivecast, ICE, or immigration enforcement in all source files we found; we were careful to distinguish infrastructure correlation from code-level confirmation. that transparency is still there in the published version and it’s not going anywhere
but you have to understand that a deployment called “onyx” appearing on your government infrastructure 12 days before publication, sharing a name with ICE’s $4.2M surveillance tool, while the current administration is running the most aggressive deportation apparatus in modern history… that’s going to raise questions. a pokemon origin story is a perfectly fine answer!!!!!! but it needs to be a documented, verifiable, and quotable answer… not something said on a call that nobody can reference later :(
re: the call, can’t do that sadly
not because i don’t trust you. you seem genuine and i appreciate the offer. but the 18 questions in section 0x14 aren’t the kind of thing that should disappear into a private zoom session. your platform holds biometric data for millions of people. it files SARs directly to FinCEN. it files STRs to FINTRAC tagged with intelligence program codenames. it runs PEP facial recognition with similarity scoring against your selfie. the people whose faces and passports are in your system deserve answers they can actually read.
private conversations are where accountability goes to die. not because of malice, but because memory is fallible, quotes get disputed, and nothing is verifiable after the fact. “we talked about it on a call” isn’t transparency, even if i recorded it.
transparency is text that anyone can read, link to, and verify.
so here’s my proposal:
answer the 18 questions in writing. take your time. i’m not trying to rush you into something sloppy. be as detailed or as high-level as you’re comfortable with. if there are things you genuinely can’t answer for legal or competitive or security reasons, say so explicitly and i’ll note it without editorializing
i will publish your full response in a second part, unedited, with whatever context or corrections you want to include. no selective quoting, no editorial spin. your words, in full, next to mine :3
if you’d prefer something more conversational, we’re open to a recorded and published conversation on signal. the format doesn’t matter but the public record does
for what it’s worth i don’t think persona is necessarily evil. the blog post ends by acknowledging what the code doesn’t show, and we meant that. i think you built a compliance platform that does what compliance platforms do, and the harder questions are about the system that makes platforms like yours necessary in the first place. but those questions still deserve answers, and “trust us” isn’t sufficient when you’re holding people’s passports and faces… especially when you have palantir in your investors, government contracts, etc etc
the blog exists because the information was already public and nobody was asking the questions. if persona wants to answer them, that’s the best possible outcome for everyone, including persona. i’d rather publish “persona addressed every concern in detail” than “persona’s CEO asked for a private call”
this email, your original message to me, and your written responses will all be published in full. everything is on the record. i want to be transparent about that upfront so there are no surprises
email works best. i don’t check twitter DMs (they have been broken for some reason)
if that wasn’t obvious already, we’re not looking for money, or anything of the sort. we just want the people to be informed
// celeste
// vmfunc.re
ps: the expired security.txt on the onyx deployment (bugcrowd program, expired 2025-11-01). you might want to renew that while you’re in there.
this email mostly speaks for itself, i think.
my the proposal was simple. i wanted an agreement on written answers, published in full.
0x03 - fedramp, onyx, and a request
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 17, 2026, 4:41 PM PST
subject: Re: Open to talking re: Persona?Thank you for responding — and genuinely appreciate how you are engaging on this.
answer the 18 questions in writing. take your time. i’m not trying to rush you into something sloppy. be as detailed or as high-level as you’re comfortable with. if there are things you genuinely can’t answer for legal or competitive or security reasons, say so explicitly and i’ll note it without editorializing
First, appreciate you offering the time for us to respond here — we’ll get back to you in a bit since we also want to be thoughtful on our responses here. If you have questions or are still interested in speaking afterwards, I am also happy to have a recorded+published conversation over Signal.
I am responding and addressing a couple of the points a bit sooner though since I have a request at the end of this email that is a bit time sensitive due to how it’s impacting people.
FedRAMP authorization implies a baseline of security controls that should catch exactly this. the fix isn’t pulling the source maps, you should fix this by explaining how this passed assessment in the first place
I think this is a really fair sentiment and you are right that this is a miss regardless. To provide some additional context here, the cluster you found is one we are actively migrating to and under development. This cluster is not the same one that was evaluated for FedRAMP (which does not have the source maps visible). This new cluster is under development to provide better reliability/redundancy which was feedback from our original assessment. However, to reiterate, you are 100% right that it is never good to have unminified typescript+source maps served to the public web and it is a miss on our end.
re: onyx and the pokemon. i hear you, and i genuinely hope that’s the real story.
I understand that it’s impossible to fully trust everything I’m saying here — and if there is any reasonable way, I am happy to confirm that this is 100% the truth. Know that screenshots don’t mean much, but will still share a couple of messages from our team who I reached out to to confirm that what I sent was accurate and to provide background on the naming which ties to the above.
Furthermore, all federal contracts are public and you can confirm that we have no federal contracts today. Transparently, we are actively working on a couple of potential contracts (hence FedRAMP), but these are entirely for the purpose of employee account security and you will be able to see these engagements publicly listed if we happen to move forward.
I am writing all of this because with this context, I have one sensitive request: would you be open to swapping the folks you’ve listed to myself/the leaders/cofounders/executives of Persona rather than individual engineers? If helpful, I can provide a list of relevant people too.
I know that all of the information you’ve shared on these individuals is public and on their social profiles, and I also know that there’s no malice in your listing of them. However, the implied tie between Palantir/ICE/Persona/betrayal from your post is leading to a lot of fear/anxiety and direct/violent threats to them particularly accusing them for something that we do not do/have never been involved in (we have no relationship whatsoever with ICE, Palantir, and the other vendors listed).
Some of the folks listed are new grads/interns/people who haven’t been at Persona for a long time, and they shouldn’t have this burden placed on them. I don’t think these people are the ones that the public’s ire should be directed at, and if anyone, it should be directed at me.
I understand the intent around transparency and don’t mind if you retain the references re: Onyx/ICE/etc. I also know that this information is public and you don’t owe us anything to make this change. However, given how things have changed for folks here, I really must ask if it’s possible to not have these individuals listed.
I would really really appreciate this change and will move as quickly as possible/do whatever I can to change this!
PS — thanks for the callout re: security.txt. Will be updated shortly.
Best,
[signature]
the fedramp cluster distinction matters here. source maps on a migration target that hasn’t been assessed yet is still bad but it’s different from source maps on the assessed production environment. persona has since published their own post-incident review on the source map exposure.
regarding the screenshots (slack, jira, CAB requests), these can’t be independently verified. screenshots are assertions, not evidence. also what you’d expect a CEO to have. the question isn’t whether they exist, it’s whether they prove what he says they prove.
here’s what he sent us:

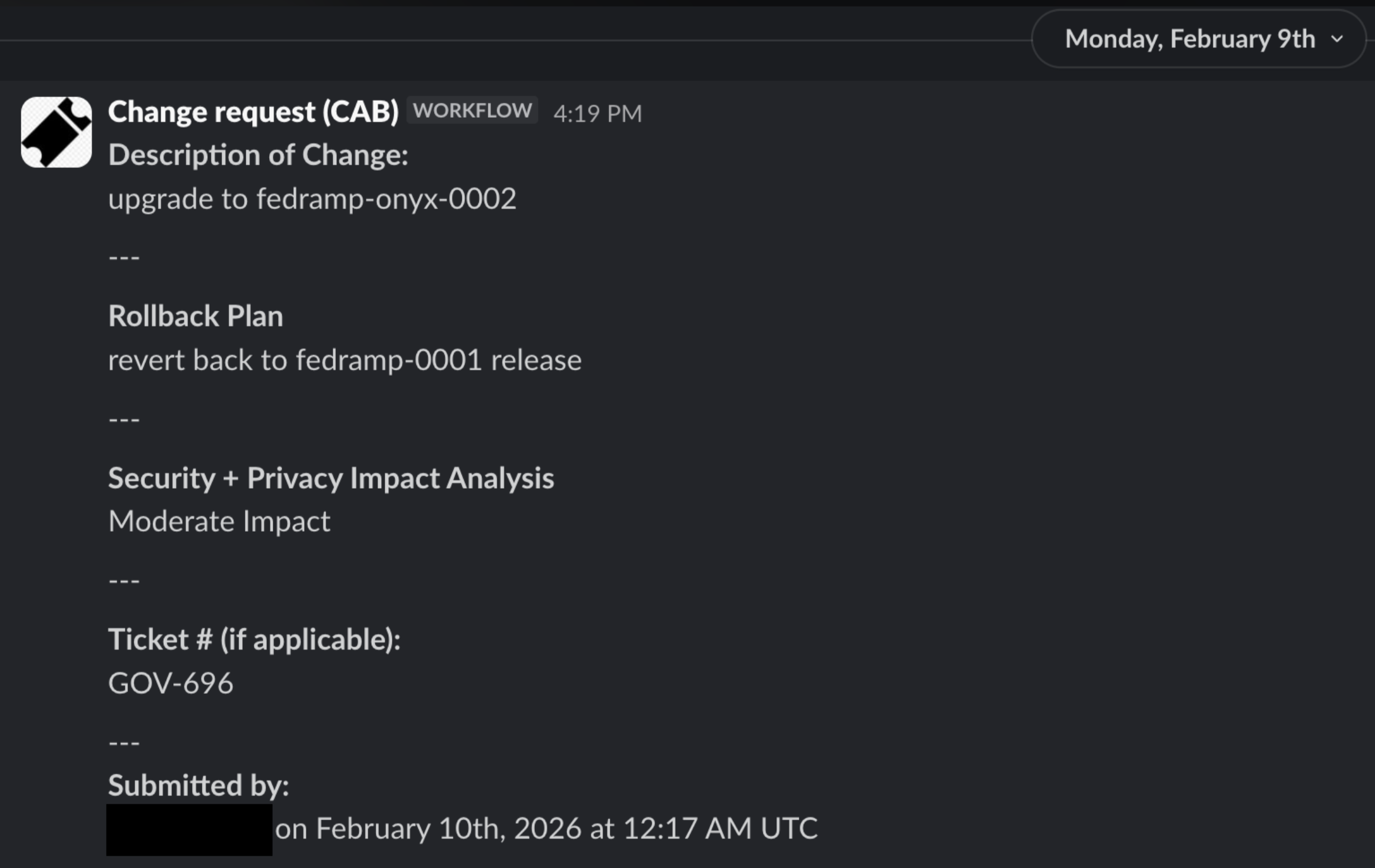
the new grads/interns thing is real though. people who wrote code comments didn’t decide to build a watchlist database. the internet can’t tell the difference between “name in a codebase” and “person who made the decisions” and that was getting people hurt. this is why we decided to remove the list from the original blog post.
so far, still nothing about openai-watchlistdb.
0x04 - the linkedin list
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 18, 2026, 5:58 AM PST
subject: Re: Open to talking re: Persona?Just to be proactive in the interest of removing the referenced individuals sooner + operating in good faith, here is a quick list of executives/leaders and their LinkedIns that can be listed.
- Rick Song - https://www.linkedin.com/in/rick-song-25198b24
- Charles Yeh - https://www.linkedin.com/in/charlesyeh/
- Christie Kim - https://www.linkedin.com/in/christiekimck/
- Duncan Sharp - https://www.linkedin.com/in/duncansharp/
- Neal Harris - https://www.linkedin.com/in/neharris/
I’ve already reached out to all of the above folks notifying them of my intent to send this note and received their consent. I can also provide more names if needed.
quick follow-up. the executives who, according to rick, consented to being named as replacements for the engineers/interns in the original post. i declined to replace these in the article as i could not verify their consent.
0x05 - the pivot
from: celeste <celeste@router.sex>
to: rick song <rick@withpersona.com>
date: february 18, 2026, 4:27 AM PST
subject: Re: Open to talking re: Persona?rick,
thank you for the screenshots. i want to be careful here because precision matters, and i owe you the same rigor i applied to the research itself.
let me tell you what i see.
i see a CEO who responded to a security publication faster than most companies respond to a CISA advisory.
i see internal slack messages from the same day you contacted me.
i see a jira ticket that could have been created any time after february 4th, which is when the onyx cert first appeared in CT logs.
i see a CAB request dated february 10th, which is six days after shodan indexed the deployment and six days before my post went live.
i see screenshots of internal tools that cannot be independently verified, because screenshots are assertions, not evidence.
i’m not accusing you of fabrication, and once again i’m trying to work in good faith, precision matters here, to both of us..
i’m telling you that the evidentiary standard for altering a published investigation is higher than screenshots of internal tools. a jira epic can be created or backdated in minutes. slack messages are timestamped from the same day you reached out. the CAB workflow is consistent with a legitimate migration AND consistent with documentation created after the deployment was noticed on shodan. i have no way to distinguish between those two scenarios from screenshots alone, and neither does anyone reading this exchange :v
if you want something stronger on the record, please write a signed public statement on persona letterhead. publish post from persona addressing the findings directly. answer the 18 questions in writing. those carry weight that slack screenshots cannot.
about the post:
i cannot in good faith and ethics silently edit a published investigation that thousands of people have already read and archived. that’s not transparency… that’s revisionism, and it’s how credibility dies.
what i will do, however, is a dated, clearly visible addendum. the original text stays intact. your context goes alongside it, visible to every reader. the addendum will note: “we are in touch with persona’s CEO and will release a part 2 of this series soon. they provided us internal documentation”
the infrastructure correlation that prompted the original questions will be noted as a legitimate observation that persona has addressed. if persona publishes a formal response, i will link to it prominently.
re: the cluster not being FedRAMP-assessed. that’s a meaningful distinction and i’ll include it in the part 2. source maps on a migration target that hasn’t undergone assessment is a different severity than source maps on the assessed production environment. accuracy matters to me even when it works in your favor!!
this is how published research handles new information. addendum. dated. transparent. the same standard i’m asking of you.
regarding the names.
i hear you about the threats. i take that seriously. trust me, i myself am victim of this daily… but i need to be direct about several things.
the section was built for transparency. the intended audience was people who already knew these individuals, family, friends, colleagues,, not a target list. if you’re genuinely connected to someone listed there, you already know who they are. you don’t need a blog post to tell you.
but i agree, the internet can’t behave. 47 years and counting, and people still can’t see a name in a research publication without deciding it’s an invitation for vigilante justice against people they don’t know at all. so the names are coming down. not because you asked to be completely honest but because people proved they can’t handle having the information without weaponizing it. that’s their fault, and it’s why they lose access to it.
not that it isn’t archived in a dozen places already. but the live post won’t carry it anymore.
also: i don’t have proof that the executives you listed consented to being named as replacements. i have your word as their CEO. consent given to one’s employer is not the same as consent given freely. if any of those individuals want to email me directly, personally, confirming they understand what being listed entails and that they’re willing, i will take that seriously. that’s a higher bar at least
the addendum will note that persona’s CEO stated these individuals are engineers, interns, and new graduates without decision-making authority over persona’s government contracts, platform architecture, or federal agency relationships. it will note that persona has reported these individuals are receiving threats as a result of the publication. it will clearly state that the section documents personnel attribution derived from source code comments, not a target list, and that threats or violence against any individual are unequivocally condemned. the methodology (source code attribution from publicly served files) will be explained so readers understand the provenance.
i will also post a tweet to discourage people to harass people. that has never been my point, and i am sorry that people on the internet did this to your engineers.
if persona wants to publish their own statement identifying their leadership team and their respective roles in the government platform’s development and federal contracting decisions, i will link to it prominently in the addendum. that gives you the outcome you’re looking for (the public knows who the actual decision-makers are) without me altering findings based on an unverifiable request from the subject of the investigation. that’s the best i can offer and stay honest and that gives you the outcome you’re looking for without me choosing who gets named on your behalf.
now.
i want to talk about the thing we haven’t talked about.
you’ve sent two emails. you addressed source maps. you addressed onyx. you addressed the personnel list. you offered screenshots, jira tickets, linkedin URLs, calls on zoom, meets, signal, discord. you’ve been generous with your time and your willingness to engage, and i don’t doubt your sincerity.
but rick, you haven’t said a single word about openai-watchlistdb?
openai-watchlistdb.withpersona.com. operational since november 2023. dedicated GCP instance. 34.49.93.177. its own SSL certificates rotating on 60-90 day cycles for 27 months straight. not behind cloudflare. not on persona’s shared infrastructure. purpose-built. isolated. running continuously since eighteen months before openai publicly disclosed any identity verification requirements to its users.
and the subdomain doesn’t say “openai-kyc” or “openai-verify” or “openai-compliance” it says watchlistdb. a database. of watchlists. for openai.
this is part the core findings. this is the one with two years of certificate transparency logs that anyone can verify on crt.sh right now, today, independent of anything i’ve published. this is the one that isn’t about a pokemon or a personnel list or a misconfigured build pipeline. this is the infrastructure that tells the story your users were never told.
the 18 questions in 0x14 are still outstanding. several of them are directly about this service. what was openai screening against in november 2023, 18 months before disclosing any identity verification requirements? does “watchlistdb” imply a proprietary watchlist beyond OFAC/SDN/PEP? what defines inclusion criteria? what happens to the data of users who are screened and denied?
you said you’d respond in writing and i believe you. but i notice that across two emails, multiple offers for calls on four different platforms, jira tickets, slack screenshots, CAB workflows, and a list of executive linkedin profiles, the watchlist database with 27 months of uninterrupted public certificate history hasn’t come up once. that silence is conspicuous, and it’s now part of the record.
i’m not in a rush. take your time. be thoughtful. but the questions won’t expire.
but please take your time, accuracy matters to me and everyone here. and thanks for taking this seriously.
cereal killer said it in 1995.. you could sit at home and do absolutely nothing and your name goes through 17 computers a day. 1984? that’s a typo. orwell is here now. he’s living large.
thirty years later, your users sit at home and do nothing and their selfie goes through 269 verification checks, gets compared against every political figure on earth with a facial similarity score, and lands on a watchlist they didn’t know existed, maintained by a company they’ve never heard of, on infrastructure that’s been running since before anyone asked them to verify anything.
the pokemon was a fine answer to a question about a name. the names are a legitimate concern about real people’s safety that i’ve addressed above. but a watchlist database with 27 months of public history isn’t a sidebar and it isn’t a naming question. it’s the question.
i look forward to the written responses.
this email, your previous messages, and your written responses to the 18 questions will all be published in full as part of the part 2. everything is on the record. i’m being transparent about that so there are no surprises on either side.
// celeste
// vmfunc.re
two emails in, rick had covered source maps (legit fix, fast), onyx (pokemon, unverifiable but plausible), the personnel list (real concern about threats), and offered calls on four platforms. all reasonable. all about everything except the central finding.
27 months of CT logs on crt.sh. anyone can check. the silence was conspicuous enough to name…
0x06 - the big one
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 18, 2026, 11:32 PM PST
subject: Re: Open to talking re: Persona?First off, I can’t emphasize how much we appreciate the changes re: removing the names on the post. It has greatly helped reduce fears/anxieties of the impacted individuals’ and I want to reiterate how appreciative I am for how quickly you did this given you didn’t have to.
i cannot in good faith and ethics silently edit a published investigation that thousands of people have already read and archived. that’s not transparency… that’s revisionism, and it’s how credibility dies.
For what it’s worth, I am aligned with this too! I think that there are some good findings + feedback in your post that we should genuinely take into consideration and reflect on. We won’t ask for any other removals or adjustments to your original post and respect your commitment to transparency and precision. The only reason for the previous ask and for my quicker responses is to avoid messages being directed at individuals here who aren’t responsible (know that my responses may not seem that fast, but it’s very rare for any potentially public statement from me to skip/bypass legal review!)
but rick, you haven’t said a single word about openai-watchlistdb?
Apologies — the lack of response on this was not to be evasive. I wanted to address the ICE/Onyx stuff first because that is the subject leading to the most severe harassment of folks here — and the source map callout is also just very fair and something we can address immediately! The delay re: OpenAI is because any statement about how a customer partners with us generally has to go through a fair bit of scrutiny and internal review given we’re a service provider and due to our contractual obligations. On reflection and with the rising tensions, I wish I had addressed this topic sooner since I can see how this may come off.
Especially given how reasonably you’ve engaged with us on this and your clear intent for transparency and accuracy, I’ve tried my best to address that subject now despite the risk it poses as our team works to answer the rest of the 18 questions.
what was openai screening against in november 2023, 18 months before disclosing any identity verification requirements? does “watchlistdb” imply a proprietary watchlist beyond OFAC/SDN/PEP? what defines inclusion criteria? what happens to the data of users who are screened and denied?
openai-watchlistdbis a single tenant deployment of our watchlist product. This product is not a proprietary database and only includes data from public records for sanctions and warning lists (OFAC/SDN). Technically, it also does not perform any lookups against PEPs.It is an entirely stateless service and does not persist any data sent to it. It was deployed as a separate tenant to support better scalability/reliability which is common for customers of their scale, and the dedicated hostname and fixed IP address were used to simplify some of the networking challenges for the integration.
Regarding why the screening happened, it is common for businesses we work with to perform sanction screens if they believe that there’s compliance/reputational risks due to adjacent laws even if they’re not in financial services, especially for businesses of greater visibility and size. Businesses often will proactively run these screens against unverified profiles to generate a high-level risk assessment for their compliance teams.
openai-watchlistdbonly screens against name, birthdate, and country. Comparisons are performed via standard practice AML attribute matching logic.Transparently, the non-OpenAI watchlist product (which, to emphasize, is not used by OpenAI) MAY do a biometric comparison against publicly available images of sanctioned individuals, but this is only done in order to help dismiss false positives on behalf of customers. For any biometrics to be processed, all of the following must be true:
- Our customer opts-in to the feature
- Biometric processing consent is explicitly displayed and collected from the individual
- The individual already matched against the other provided attributes (if they did not match, then no biometric processing is performed).
Our customers determine which checks are run/processed (including the aforementioned) and enable/disable/configure them via our platform. Many of the more sensitive checks are gated and require additional due diligence from our compliance team to ensure that the use case is permissible and that proper consent is being surfaced, collected, and stored. Customers are in full control of how decisions are made using these checks, and we do not recommend that decisions are fully automated in all cases, especially if there is a case of rejection (often, customers perform additional review for potential false declines via our Cases product). Persona also does not perform any manual reviews to determine a decision on behalf of any customers to reduce the threat of a data breach emerging from our team.
Customers configure and control all retention policies for data. Persona also has a max global retention period that limits how long a customer may retain data. The only contractually permissible purposes to retain data collected via Persona is to satisfy legal/audit requirements or combat fraud, and the majority of data processed by our platform is redacted immediately after completion.
No data processed on behalf of OpenAI is sent to FinCEN or FINTRAC via Persona. Our FinCEN and FINTRAC integrations are used by financial institutions and require them to integrate using their own filing credentials to assist with e-filings. The vast majority of our customers do not have filing credentials, and to note, Persona also does not have its own filing credentials.
Because our frontend code is a superset of all features on our platform, you will see references to things that many customers do not have access to.
if you want something stronger on the record, please write a signed public statement on persona letterhead. publish post from persona addressing the findings directly. answer the 18 questions in writing. those carry weight that slack screenshots cannot.
I asked our legal team to put together a signed statement on Persona letterhead — the statement is admittedly not the most legally standard, but it’s framing also helps it cover a broader range due to it applying to both past and future correspondences (including the screenshots I’ve provided and the future responses to your questions).
Furthermore, I understand our response to your questions have taken longer than desired. Although we’re not by any means a large company, we are large enough now where there is a good amount of processes and bureaucracy for us to work through in the pursuit of accuracy and transparency. These correspondences are coming directly from me to address these topics more quickly, particularly the ones impacting individuals on our team. Also want to share that the delays of my replies are only because I’m personally writing these after meetings during the work day, not due to any desire to be evasive. Hopefully through these responses, I’ve been able to address a subset of the questions too (to emphasize, we have full intent to respond to all of them to the best we can).
Given your fair perspective that the public deserves transparency about what Persona is doing and in the hopes that it may tone down the understandable fear/concerns the public has of things we are not doing (and selfishly, to also reduce some of the extreme rhetoric targeted at us), I would genuinely appreciate if you would be open to publishing our correspondences sooner. Unfortunately, the amount of harassment and threats has increased today as your post continues to gain traction. Meanwhile, I’ll work with our team to move faster on the questions — we were originally hoping to respond by the start of next week, but will aim for sooner given the increased tensions.
Best,
[signature]
rick finally talked about openai-watchlistdb!
his position is that this was a single-tenant deployment, OFAC/SDN only, with no PEP lookupsm, and stateless. he claims no data persistence. name, birthdate, country only. standard AML attribute matching. dedicated hostname/IP for networking simplification.
that’s a meaningful narrowing from what the source code implies. the frontend has SelfieSuspiciousEntityDetection, SelfieExperimentalModelDetection, PEP facial similarity scoring
rick says the frontend is a superset of all platform features and openai’s tenant only uses a subset. plausible (multi-tenant SaaS works this way) but i can’t verify it from the outside.
the three-gate biometric model for non-openai customers is interesting, though.
apparently, customer opts in, consent explicitly displayed and collected from the individual, prior attribute match required before any biometric processing runs. doesn’t make the capability less concerning but it shows someone thought about when and how it fires, which somewhat reassures me a little bit.
“no data processed on behalf of OpenAI is sent to FinCEN or FINTRAC via Persona”
this was the biggest conspiracy after part 1 was that openai user data was getting filed to the feds through persona.
rick says that persona doesn’t have its own filing credentials, customers bring their own, openai doesn’t use the integration.
i can’t verify any of that, but he said it in writing, knowing it gets published. if it holds up, good. if it doesn’t, it’s a documented false statement from a CEO. either way it’s on the record now.
the frontend-as-superset thing is also why source maps on a government endpoint can’t be public. the code doesn’t distinguish between what’s active for a specific customer and what’s a platform-wide capability. neither can anyone reading it.
12 of the 18 questions still outstanding. he’s asking to publish sooner because the harassment is getting worse.
understandable, but the correspondence isn’t done yet.
0x07 - the signed statement
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 19, 2026, 10:18 AM PST
subject: Re: Open to talking re: Persona?Celeste,
I was just notified that you posted the signed statement without any additional context. Unfortunately, this is adding even more fuel to the conspiratorial things online.
Folks have shared posts such as this making claims about ties linking the US government to public FINTRAC programs which are Canadian (e.g. Project Legion which is to stop Money Laundering via Cannabis or Project Shadow which is to stop CSAM). There are far worse conspiratorial posts being pushed now using the statement as implied affirmation to what’s happening.
I know you’ve shared that you’re operating in the spirit of transparency and ethical hacking. I’ve also trusted that you are operating with the best intentions for the public and in good faith. However, I genuinely don’t think your most recent action of posting my signed statement without any additional context helps on any of these fronts. If anything, it has done the opposite and led to more misinformation, more outrage, and more threats.
Please publish these correspondences as soon as possible. Our team may need to simultaneously publish these correspondences now to provide folks with context too.
the signed statement in question: rick_song_persona_declaration.pdf
he’s right about this one. posting the signed statement without the full correspondence alongside it created a vacuum that people filled with whatever confirmed their priors.
project legion is a canadian AML program targeting cannabis money laundering. project shadow is anti-CSAM. neither has anything to do with persona. but the statement referenced them, and without rick’s explanations sitting next to it for context, people drew connections that aren’t there.
the conspiracies were already building before the statement went up, though…
the ONYX name, the FinCEN interface, the FINTRAC references in the codebase, all that was in the original findings and people were connecting dots from day one. the statement didn’t start it, but i believe it gave people something official-looking to point at without the context to read it properly. that was my mistake.
0x08 - the personal one
from: celeste <celeste@router.sex>
to: rick song <rick@withpersona.com>
date: february 19, 2026, 12:37 PM PST
subject: Re: Open to talking re: Persona?rick,
going to ask that this one stays on the record. my response here gets personal in places
re: the signed statement
you’re right that posting it without the correspondence alongside it created a vacuum that people filled with whatever confirmed their priors. project legion is a canadian AML program for cannabis trafficking. project shadow is anti-CSAM. neither has anything to do with persona. but without your responses sitting next to the statement for context, people drew connections that aren’t there and i understand how that made things worse for you and your team. that’s on me, i should have published everything together or waited.
to be fair the conspiracies were already building before the statement went up… the ONYX name, the FinCEN interface, the FINTRAC references in the codebase, those are all in the original findings and people were connecting dots from day one. the statement didn’t start it but it gave people something official-looking to point at without the context to read it properly. sorry about that, genuinely.
ok. watchlistdb.
your response here is actually really helpful and i want to engage with it properly because this is going into part 2 and i want to represent what you said accurately.
single-tenant deployment for scalability, stateless, no data persistence, OFAC/SDN only, no PEP lookups is a meaningful narrowing of scope from what the code on its own implies. the dedicated hostname/IP for networking simplification makes sense architecturally. i appreciate you being specific about this because vague answers are what feeds speculation.
the three-gate model on the non-openai biometric comparison (customer opt-in to consent displayed and collected to prior attribute match required before any biometric processing)!!!!!!!! this is the kind of specificity that actually matters for the public conversation. doesn’t make the capability less concerning in the abstract but it shows there’s intentional design around when and how it gets used. worth publishing
few things your response opens up that i want to flag for the remaining questions:
you say openai-watchlistdb screens name, birthdate, country only. the codebase contains SelfieSuspiciousEntityDetection, SelfieExperimentalModelDetection, PEP facial similarity scoring. i get the frontend is a superset of platform features. but can you confirm which checks are actually active in openai’s tenant vs what exists as general platform capability? that gap between “what the code can do” and “what this specific customer’s configuration does” is where most of the fear is coming from right now. getting that distinction on the record would help a lot.
you say majority of data is redacted immediately after completion, customers control policies with a global max. code references suggest 3 years max. openai publicly says up to a year. what’s persona’s actual global retention cap and does openai’s config fall within it?
the FinCEN/FINTRAC sentence is the single most important thing in your entire response. “no data processed on behalf of openai is sent to FinCEN or FINTRAC via persona” that needs to be front and center when we publish because it directly addresses the biggest conspiracy going around right now.
re: frontend code being a superset
i hear you and i understand how that works architecturally. but that’s also exactly why source maps on a government endpoint can’t be public… the code doesn’t distinguish between tenant-specific features and platform-wide capabilities, and neither can anyone reading it. that’s the core of the disclosure issue.
i’ll publish the full correspondence this week. both sides unedited, in context. your team publishing simultaneously from persona’s side genuinely helps, would means neither of us is the only narrator and people can verify against both versions. my analysis will be separate from the correspondence, clearly marked.
also just being straightforward here because i think you’d prefer that: discord ended the persona experiment this week. EFF published a piece. PC Gamer, Kotaku, and as of today The Rage are all running coverage. they’re working with fragments because the full context doesn’t exist publicly yet. the window for persona to get its side out with the full correspondence as backing is right now
re: harassment escalating
i’m sorry. i know what that feels like and i wouldn’t wish it on your team, especially people who didn’t make the architectural or contractual decisions being scrutinized. names stay down
we just wanted to know which computers your name goes through. that’s all this has ever been
and since this is on the record and i’m being honest anyway:
i’m 20. i know you know that already but i think it matters for context here. i’ve been doing this since i was a kid, finding things, writing about them, publishing what i find. it’s genuinely the only thing i’ve ever been good at. and every single time something i publish gets traction, the same cycle plays out: the research gets attention, then the person behind the research gets attention, and then people who have nothing to do with any of it start sending emails to whoever they think will hurt me the most.
i’m telling you this because you’re living through the other side of the same thing right now and i think you already get it. people are sending you emails that have nothing to do with persona or watchlistdb or source maps. people are sending me emails that have nothing to do with the research. the harassment isn’t a side effect of publication… it’s a parallel industry that attaches itself to anything visible and feeds off the attention. we’re both just… currently the thing it’s feeding on.
i also want to say something that probably doesn’t belong in a professional correspondence but i don’t really care:
you didn’t have to engage with me like this. most CEOs in your position would have sent a legal letter, cc’d outside counsel, and never spoken to me directly. you emailed me at 4am from your personal account and asked to talk. you responded to a security researcher publishing your company’s source code by… being a person about it. that’s rare and i notice it and i won’t forget it
the research isn’t personal. it was never about you. but this exchange has become personal, in a good way, and i think the public benefits from seeing that too. two people on opposite sides of a disclosure who managed to just… talk to each other.
i’m not going to editorialize this one. it says what it says.
0x09 - the strongest claim
from: rick song <rick@withpersona.com>
to: celeste <celeste@router.sex>
date: february 20, 2026, 1:56 AM PST
subject: Re: Open to talking re: Persona?Hi Celeste,
Thank you for the latest response. I apologize for taking things to Twitter. You are right that it was not the most effective way to communicate. I’ve since deleted the majority of my posts because they were just baiting engagement and weren’t helping reduce misinformation at all. I also appreciate your kind words and agree with your sentiment about how everything has unfolded.
you say openai-watchlistdb screens name, birthdate, country only. the codebase contains SelfieSuspiciousEntityDetection, SelfieExperimentalModelDetection, PEP facial similarity scoring. i get the frontend is a superset of platform features. but can you confirm which checks are actually active in openai’s tenant vs what exists as general platform capability? that gap between “what the code can do” and “what this specific customer’s configuration does” is where most of the fear is coming from right now. getting that distinction on the record would help a lot.
I can make a stronger statement about
openai-watchlistdb: it’s a simplified deployment of our Watchlist product (sanctions and warning lists) that has no code references whatsoever to any biometric processing. This means that the deployment contains no code referencing biometrics of any form (including SelfieSuspiciousEntityDetection, SelfieExperimentalModelDetection, PEP facial similarity scoring). It is a very simple service — it only performs one check (standard AML attribute matching on name, birthdate, and country) and produces potential match results and metadata regarding the match comparison.Regarding PEP v1 and v2 and the known incompatibilities from your previous set of questions: these exist due to published changes in guidances around how PEP screening should be handled over time. We need to help migrate customers as the standards or even just best practice recommendations change.
The requirements for PEP biometric matching (and facial similarity scoring) have the same controls as watchlist biometric matching. In particular, for any biometrics to be processed, all of the following must be true
- Our customer opts-in to the feature
- Biometric processing consent is explicitly displayed and collected from the individual
- The individual already matched against the other provided attributes (if they did not match, then no biometric processing is performed)
For additional context, we added the option for customers to enable biometrics to automatically dismiss false positives because >99% of Watchlist+PEP hits are false positives. False positives are a massive problem in the industry (as you can see from how few attributes you are matching against). When a false positive occurs, the organization blocks the individual from opening a financial account until the match is resolved. This often occurs for the same individual across all organizations they sign up for. Furthermore, matches disproportionately affect a small number of people — the top 20 watchlist entries cause more than 40% of all false positives across all our customers.
We believe the leveraging biometrics to automatically resolve false positives for Watchlists/PEPs matches has been a major net positive for both organizations (who constantly resolve the same false positives) and for the individual (who no longer experiences delays in account opening for every service they sign up for), particularly because this feature can never hurt and only improve the experience for all parties involved.
To re-emphasize, OpenAI does not use biometrics for Watchlists and does not use our PEP product at all.
you say majority of data is redacted immediately after completion, customers control policies with a global max. code references suggest 3 years max. openai publicly says up to a year. what’s persona’s actual global retention cap and does openai’s config fall within it?
Persona’s max retention period is 3 years, and OpenAI’s policy of 1 year falls well below the max and therefore takes precedence. For sensitive use cases like age verification, we schedule data redaction immediately after completion.
One thing lost from my original tweet that I wish I could’ve preserved is that I genuinely admire your talent and continue to believe you have a tremendous amount of potential to do even greater things for the world, especially in cybersecurity, an area that I care deeply about given our work at Persona. I don’t think you should talk down your talent (your research on forging passkeys for example is fantastic), and I will still look forward to your future posts (preferably not about Persona, but even if it is, I will still look forward to it). And if you ever have questions or want to engage directly with me in the future, you can email me any time.
Best,
[signature]
“no code references whatsoever to any biometric processing”
not “we don’t use biometrics for openai” (policy obviously… could change tomorrow) but “the deployment contains no code referencing biometrics of any form” (a claim about what exists in a specific codebase right now)
if that codebase ever gets audited or leaked, this statement lives or dies on contact with reality.
i can’t see it. i can’t audit it. but he said it knowing it gets published. that’s either confidence or recklessness.
the false positive data is genuinely interesting to me though
99% of watchlist/PEP hits are false positives. top 20 entries cause 40%+ of all false positives across all customers.
that’s… a window into how broken sanctions screening is at a fundamental level. your system catches 1 real hit for every 99 innocent people it blocks. the biometric opt-in exists to fix a system that doesn’t work. more honest framing than most compliance companies would ever admit to.
regarding PEP v1/v2, published guidance changes driving migration. normal compliance lifecycle stuff. the reference is verifiable.
about retention, he claims 3 years global cap, openai at 1 year, and age verification redacted immediately.
0x0A - the record
from: celeste <celeste@router.sex>
to: rick song <rick@withpersona.com>
date: february 20, 2026, 5:14 AM PST
subject: Re: Open to talking re: Persona?rick,
thank you for this. genuinely.
the twitter thing, for what it’s worth i wasn’t going to hold it against you… CEOs under pressure do dumb things on twitter, that’s basically a law of physics at this point. the fact that you course-corrected on your own says more than the posts did
about watchlistdb.
“no code references whatsoever to any biometric processing” is the strongest statement you’ve made in this entire exchange.
i want to be precise about what that means for the record: it’s a falsifiable claim about a specific deployment that i have no way to independently verify.
i can’t see openai-watchlistdb’s codebase. i can’t audit its configuration. i can’t confirm that a simplified deployment exists as described vs the full platform deployment the shared frontend implies.
what i CAN say is that you’ve now made this claim in writing, under the signed statement, in a correspondence you know will be published. that carries weight. if it’s accurate, it materially narrows the scope of what the service does. if it’s not, it’s a documented false statement from a CEO on the record. i’ll present it as exactly what it is, it’s persona’s position, stated clearly and unverified independently
same applies to the stateless claim. an entirely stateless service that doesn’t persist data is a specific architectural assertion. the CT logs show 27 months of continuous operation with regular cert rotation, which is consistent with a live stateless service but also consistent with a stateful one. i can’t distinguish between them from the outside. your statement narrows the possibilities but doesn’t eliminate them. i’ll note that!!
about PEP v1/v2, published guidance changes driving migration is a normal compliance lifecycle thing, and the reference you linked is verifiable. i’ll contextualize the “known incompatibilities” accordingly in part 2, thank you
getting a second confirmation for biometrics here is useful. the false positive data is genuinely interesting?
i want to be transparent about my methodology here because i think you deserve that
everything you’ve told me goes into part 2. none of it gets editorialized but i will consistently note what i can verify independently (CT logs, DNS, shodan, public documentation, the source code itself) vs what relies on your representations.
i think readers deserve to know the difference, and honestly it protects you too. if your statements hold up to future scrutiny, the fact that i flagged them as unverified makes their eventual confirmation stronger
this has been one of the most unusual exchanges i’ve had with the subject of a publication. you didn’t lawyer up. you didn’t threaten. you apologized for going to twitter before i even asked you to. you answered the watchlistdb questions knowing the answers would be published and knowing i’d push back on anything that didn’t hold up.
also that last paragraph, i don’t know if your comms team told you to write that or if that was just you being a person, but either way, it landed.
i’m going to be honest with you the way you’ve been honest with me
this exchange restored some of my faith in how disclosure can work. most of the time it’s lawyers and silence and NDAs and threats
but the remaining questions from 0x14 that haven’t been addressed yet still need answers. you’ve covered a meaningful subset here and i appreciate the pace you’re moving at given legal review. the rest need responses before part 2 goes up. take the time to be accurate!!!!
so you don’t have to dig through that chain again, here’s where we stand on the 18, i believe
you’ve addressed 1, 2, 6, 11, 13, and 17. partially covered 9 and 10
Q3, which federal agencies use withpersona-gov.com? the code is agency-agnostic and you’ve said you have no federal contracts today but are working on a couple. which agencies are those potential contracts with?
Q4, what defines a “suspicious entity” in SelfieSuspiciousEntityDetection? what facial characteristics or signals trigger this flag?
Q5, what do SelfieExperimentalModelDetection and IdExperimentalModelDetection actually do? unnamed ML models running on live biometric data needs an explanation.
Q7, has persona performed a BIPA compliance assessment for Illinois residents? given “millions” of monthly screenings and biometric collection, the statutory exposure is real.
Q9 (partial), you covered retention but didn’t address: can law enforcement access the data of users who are screened and denied? under what legal process?
Q10 (partial), you confirmed the AI copilot is productivity tooling. what data context does it have access to? can it see PII, biometric results, SAR drafts, watchlist hits?
Q12, were users informed that their selfie undergoes public figure facial matching? that the platform checks whether your face resembles a known politician and assigns a similarity score?
Q14, who authorized liveness/spoof detection that assigns “High Risk” labels recommending automatic rejection? what is the false positive rate on that determination?
Q15, why does a FedRAMP platform include FINTRAC filing capability? which agencies have cross-border filing capability?
Q16, the source code references AES-256-GCM encryption keys with a comment about “depending on obfuscation.” did FedRAMP assessors review this?
Q18, are users informed that 269 distinct verification checks are performed, including SSN death record matching, phone carrier queries, and PDF metadata analysis?
publication is the pressure relief valve here, not the escalation i believe
the harassment cycle slows down when people have answers instead of gaps to fill with their worst assumptions. i’ve been on both sides of that and i promise you it’s true.
i’ll be in touch before part 2 goes live so there are no surprises. same standard as before
thanks for the passkeys shoutout btw. that one was fun :3
// celeste
// vmfunc.re
0x0B - the scorecard
here are the 18 questions from part 1, section 0x14, where they stand after the correspondence.
answered:
- Q1 - what was openai screening against in november 2023? OFAC/SDN sanctions lists via standard AML attribute matching on name, birthdate, country. proactive compliance screening common for high-visibility businesses.
- Q2 - does “watchlistdb” imply a proprietary watchlist? no. public records only - OFAC/SDN. no proprietary database. no PEP lookups for openai.
- Q6 - what is the actual biometric retention period? persona global cap: 3 years. openai policy: 1 year (takes precedence). age verification: redacted immediately after completion.
- Q11 - what is the relationship between persona’s “onyx” and fivecast ONYX? persona’s position: named after a coworker’s favorite pokemon. no association with ICE. no federal contracts currently active. unverifiable but consistent with the absence of ICE/fivecast references in the source code.
- Q13 - how did source maps end up on a FedRAMP endpoint? the cluster found was a migration target under development, not the assessed production environment. source maps were an oversight. acknowledged as a miss. persona published a post-incident review.
- Q17 - PEP v1/v2 incompatibilities and false positives? published guidance changes driving migration. >99% of watchlist/PEP hits are false positives. top 20 entries cause >40% of all false positives. biometric opt-in exists to automatically dismiss false positives.
partially answered:
- Q9 - what happens to data of screened/denied users? retention policies addressed (customer-controlled, global max). law enforcement access and legal process not addressed.
- Q10 - AI copilot data access? confirmed as productivity tooling. specific data context (PII, biometric results, SAR drafts, watchlist hits) not addressed.
- Q18 - are users informed about the 269 verification checks? rick addressed this publicly on twitter, calling some implications about persona’s capabilities “patently false.” stated persona offers on-device age verification and was transparent with discord about technological limitations. disputes the characterization of what checks run but doesn’t directly address whether users are notified about the full scope of checks performed.
unanswered:
- Q3 - which federal agencies use withpersona-gov.com?
- Q4 - what defines a “suspicious entity” in SelfieSuspiciousEntityDetection?
- Q5 - what do SelfieExperimentalModelDetection and IdExperimentalModelDetection do?
- Q7 - has a BIPA compliance assessment been performed?
- Q8 - why is Ukraine blocked alongside OFAC-sanctioned countries?
- Q12 - were users informed about public figure facial matching?
- Q14 - who authorized liveness/spoof detection with automatic rejection?
- Q15 - why does a FedRAMP platform include FINTRAC filing?
- Q16 - “depending on obfuscation” for encryption keys - FedRAMP review?
new information provided (not asked for):
- the three-gate biometric model (customer opt-in → consent collected → prior attribute match required)
- false positive statistics (>99% false positive rate, top 20 entries = 40% of false positives)
- retention specifics (3-year global cap, immediate redaction for age verification)
- the FinCEN/FINTRAC denial (“no data processed on behalf of OpenAI is sent to FinCEN or FINTRAC via Persona”)
- openai-watchlistdb as stateless service with no data persistence
- frontend-as-superset architectural explanation
- “no code references whatsoever to any biometric processing” in openai-watchlistdb
6 answered. 3 partial. 9 silence. but some of the most important things rick said weren’t even answers to questions i asked.
the FinCEN/FINTRAC denial and “no code references to biometrics” weren’t in the original 18 and he volunteered those.
of course, i would like you to remember that most of these facts are unverifiable from the outside. but we are publishing this for transparency. best case scenario, this is all true. worst case scenario, a CEO lied on the record with a signed statement.
0x0C - what we know now
i separated this in two categories, things i can check myself, and things i’m can only take rick’s word for.
what i can verify (same as part 1, nothing changed):
- openai-watchlistdb.withpersona.com operational since november 2023 (CT logs on crt.sh, go look)
- 27 months of cert rotation on 60-90 day cycles
- dedicated GCP instance at 34.49.93.177 (shodan)
- the source code contains everything part 1 found, 269 checks, biometric processing, PEP facial matching, SAR/STR filing, all of it (source maps pulled now but the code was already archived)
- onyx deployment had zero references to ICE, fivecast, or immigration enforcement in source
what rick says (unverified):
- openai-watchlistdb: name, birthdate, country only. no biometrics. no PEP. stateless. no data persistence
- “no code references whatsoever to any biometric processing” in that deployment
- no openai data goes to FinCEN or FINTRAC through persona. persona doesn’t have its own filing credentials
- frontend code is a superset - customer configs determine what’s active per tenant
- biometric processing needs all three gates (customer opt-in, consent collected, prior attribute match)
- the FedRAMP cluster with source maps was a migration target, not the assessed one
- onyx = pokemon
- no federal contracts active. potential ones are for employee account security
- 3 year global retention cap. openai at 1 year. age verification redacted immediately
rick also posted a public statement on twitter that reinforces and extends several of these positions:
- “we were not hacked or breached” (source maps were an oversight, not a compromise)
- “we do not send your identity to the government” - financial services customers can file AML reports through the platform, but persona doesn’t do it on their behalf
- “we do not use your data to train AI”
- “we do not work with ICE or the DHS”
- “we do not work with any federal agency” - competing for contracts to authenticate remote government employees
- “we do not work with Palantir”
- “we do not interact with Peter Thiel” - but took money from Founders Fund, which he cofounded
- customers are generally the data controller (GDPR sense). persona schedules deletion of any data they control after verification
- “we have no interest in your data. we do not profit off it. in fact, it’s the opposite. the liability is too great and the fines are too high.”
same caveats as above - these are assertions from a CEO on a public platform. can’t independently verify most of them. but they’re on the record now and that matters.
the Palantir/Thiel distinction is worth noting. “we don’t work with palantir” and “we don’t interact with peter thiel” are carefully scoped statements. founders fund is a VC firm. taking their money doesn’t mean palantir has access to persona’s systems or data. but it does mean the money is in the cap table, and that’s the kind of thing people notice when your platform holds biometric data.
the FinCEN/FINTRAC denial is the big one. because that was one of the conspiracies.
openai user data getting filed to the feds. rick says no. i can’t check. but it’s in writing now.
“no code references to biometrics” is the most falsifiable though. that’s not a policy position but rather a claim about a specific codebase. if that code ever surfaces, the claim either holds or it doesn’t.
i can’t confirm the stateless thing from the outside. a stateless service and a stateful one look identical on the network. cert rotation happens either way.
0x0D - what we still don’t know
Q3 - which federal agencies? rick said no contracts today, working on a couple. which agencies? this becomes public once contracts execute.
Q4 - what’s a “suspicious entity” in SelfieSuspiciousEntityDetection? what makes your face suspicious?
Q5 - SelfieExperimentalModelDetection, IdExperimentalModelDetection. unnamed ML models on live biometric data. what do they do?
Q7 - BIPA compliance for Illinois residents? “millions” of monthly screenings, biometric collection. the statutory exposure is real.
Q8 - why is Ukraine blocked alongside OFAC-sanctioned countries? Ukraine isn’t sanctioned. (might be openai’s call, not persona’s - but the platform implements it.)
Q9 (remaining) - can law enforcement access data of users who get screened and denied? under what legal process? rick covered retention but not access.
Q10 (remaining) - what can the AI copilot see? PII? biometric results? SAR drafts? watchlist hits? confirmed as productivity tooling but scope is still a black box.
Q12 - does anyone tell users their selfie gets compared to politicians with a facial similarity score?
Q14 - liveness/spoof detection assigns “High Risk” labels and recommends automatic rejection. who authorized that? what’s the false positive rate?
Q15 - FINTRAC filing on a FedRAMP platform. the credentials explanation helps but doesn’t explain why it’s there at all.
Q16 - AES-256-GCM keys with “depending on obfuscation” in the comments. did FedRAMP assessors see that?
Q18 - rick addressed this on twitter, calling claims about persona’s capabilities “patently false” and stating persona offered on-device age verification to discord. disputes the framing but doesn’t directly answer whether users are informed about the full scope of checks. partially addressed.
the pattern is worth noting. rick answered the openai-watchlistdb questions. he answered about scope, data types, biometrics, retention, FinCEN. the ones he didn’t touch are about the platform itself. the experimental ML models, the suspicious entity detection, BIPA, user notification, encryption, law enforcement access.
those aren’t gotcha questions but those are the ones that affect every person whose face goes through this system. not just openai’s users… everyone.
0x0E - epilogue
this is what disclosure looks like when it works, i believe.
not perfectly of course, as the signed statement timing was my mistake, the conspiracies got ahead of the context, people who had nothing to do with any of this received threats. none of that should’ve happened.
but underneath all that noise, a CEO emailed at 4am. i said answer in writing, everything gets published. he said ok. and then he did it. no lawyers. no NDAs. no DMCA. no threats. just… answers. some of them, anyway.
you could sit at home and do absolutely nothing and your name goes through 17 computers a day.
thirty years later we sat at home and asked which computers. and someone answered. not all the way, as 12 questions are still open, but more than anyone expected and more than most companies would ever allow.
the questions don’t expire. another part or statement follows if the remaining 12 get the same treatment!
the information wants to be free. and i suppose, sometimes, rarely, at 4am from a CEO’s personal email, it comes to you.
stay curious. stay paranoid. publish everything. even the parts where you were wrong… especially those.
// end of transmission //